
¿Quieres saber qué es el contenido duplicado y cómo podría estar perjudicando tu SEO? El contenido duplicado es una fuente de ansiedad constante para muchos propietarios de sitios web.

Si leemos cualquier artículo al respecto saldremos creyendo que nuestro sitio es una bomba de tiempo de problemas de contenido duplicado. Pensaremos que una penalización de Google está a solo unos días de distancia.
Afortunadamente, esto no es cierto, pero el contenido duplicado aún puede causarnos problemas de SEO. Además, con el 25 al 30% de la web siendo contenido duplicado, es útil saber cómo evitar y solucionar estos problemas.
Índice
- 1 ¿Qué es el contenido duplicado?
- 2 ¿Por qué el contenido duplicado es malo para el SEO?
- 3 ¿Google penaliza el contenido duplicado?
- 4 Causas comunes de contenido duplicado
- 4.1 Navegación por facetas o facetada/filtrada
- 4.2 Parámetros de seguimiento
- 4.3 ID de sesión
- 4.4 HTTPS vs HTTP, y sin www vs www
- 4.5 URLs sensibles a mayúsculas y minúsculas
- 4.6 Barras al final vs sin barras al final
- 4.7 URLs fáciles de imprimir
- 4.8 URLs compatibles con dispositivos móviles
- 4.9 URL de AMP
- 4.10 Páginas de etiquetas y categorías
- 4.11 URLs de imagen adjunta
- 4.12 Comentarios paginados
- 4.13 Localización
- 4.14 Páginas de resultados de búsqueda
- 4.15 Entorno provisional
- 4.16 ¿Cómo verificar si hay contenido duplicado en nuestro sitio?
- 4.17 ¿Cómo verificar si hay problemas de contenido duplicado en la web?
- 4.18 Republicar contenido en nuestro propio sitio web
- 5 Conclusiones
¿Qué es el contenido duplicado?
El contenido duplicado es todo contenido exacto o casi duplicado que aparece en la web en más de un lugar. Puede ocurrir en un solo sitio web o dominio cruzado. Por ejemplo, si tuviéramos que volver a publicar esta guía:
ayudahosting.online/guía-completa-contenido-duplicado-copy/
Entonces sería contenido duplicado. Eso también sería cierto si tuviéramos que volver a publicarla en otro sitio web.
Google afirma que la mayoría del contenido duplicado no es de origen engañoso.
¿Por qué el contenido duplicado es malo para el SEO?
El contenido duplicado puede dañar nuestro rendimiento SEO por varias razones.
- Por tener URLs indeseables o poco amigables en los resultados de las búsquedas.
- También por dilución de un enlace de retroceso.
- Por no ser tomados en cuenta en el rastreo.
- Contenido Scraped o sindicado que nos supera.
Exploremos estas causas que pueden dañar nuestro SEO con más profundidad.
URLs indeseables o poco amigables en los resultados de las búsquedas
Imaginemos que la misma página está disponible en tres URLs diferentes:
- dominio.com/pagina/
- dominio.com/pagina/?utm_content=bufferyutm_medium=sociales
- dominio.com/categoria/pagina/
La primera debería aparecer en los resultados de búsqueda, pero Google puede equivocarse. Si eso sucede, una URL no deseada puede ocupar su lugar.
Debido a que las personas pueden estar menos inclinadas a hacer clic en una URL hostil, podemos obtener menos tráfico orgánico.
Dilución de un vínculo de retroceso
Si el mismo contenido está disponible en muchas URLs, entonces cada una de esas URLs puede atraer vínculos de retroceso. Eso da como resultado la división de la equidad del enlace entre las URLs.
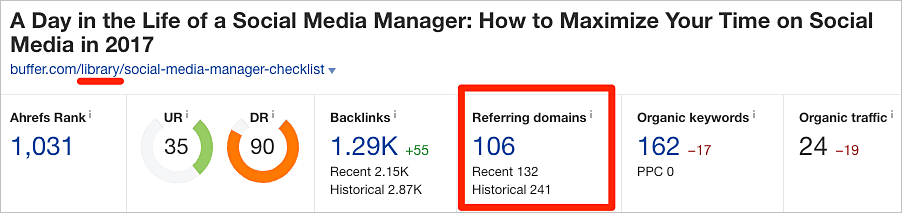
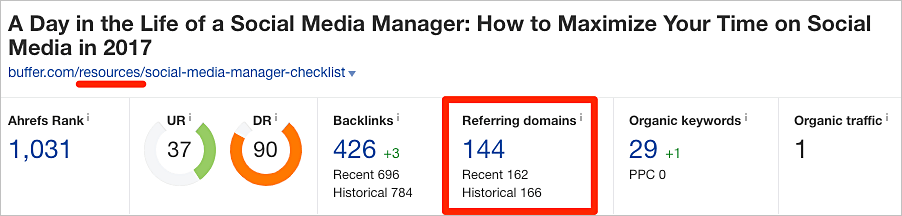
Para mostrar un ejemplo práctico, echemos un vistazo a estas dos páginas en buffer.com:
https://buffer.com/library/social-media-manager-checklist https://buffer.com/resources/social-media-manager-checklist
Estas páginas están duplicadas casi exactamente. Y tienen 106 y 144 dominios de referencia (enlaces de sitios web únicos), respectivamente.
Antes de entrar en pánico, debemos saber que esto no siempre es un problema debido a cómo Google maneja el contenido duplicado.
En términos muy sencillos, cuando Google detecta contenido duplicado, agrupa las URL en un clúster. Luego selecciona cual cree que es la mejor URL para que represente el clúster en los resultados de búsqueda y consolidar las propiedades de las URLs del clúster, como la popularidad del enlace, para la URL representativa.
Entonces, en el caso anterior, Google debería mostrar solo una de las URL en la búsqueda orgánica y atribuir todos los dominios de referencia en el clúster (106 + 144) a esa URL del ejemplo.
Sin embargo, eso no es lo que sucede. Ya que vemos que ambas URL se clasifican en Google para palabras clave similares.
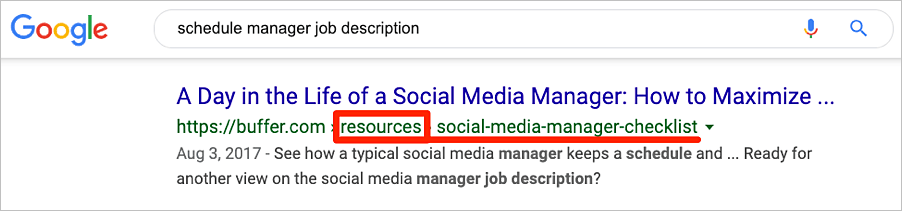
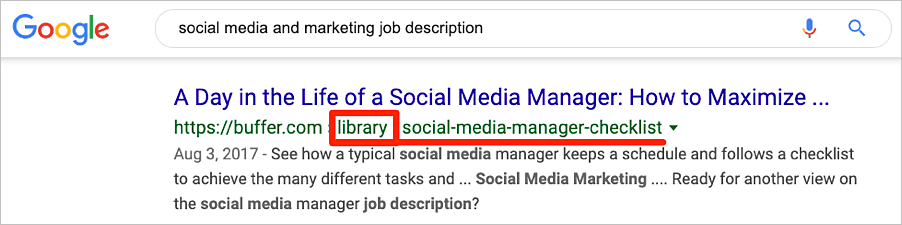
En este caso, es probable que Google no esté consolidando la equidad del enlace en una URL.
Nota: No podemos estar seguros de cómo ve Google estas dos URL, ya que no tenemos acceso a la cuenta de Buffer de Google Search Console. Puede ser que Google vea estas dos URL como duplicadas, y una de ellas desaparecerá pronto de la búsqueda orgánica.
Por no ser tomados en cuenta en el rastreo
Google encuentra contenido nuevo en nuestro sitio web a través del rastreo o crawl, lo que significa que sigue los enlaces de páginas existentes a páginas nuevas. También vuelve a rastrear páginas que conoce de vez en cuando para ver si algo ha cambiado.
Tener contenido duplicado solo sirve para aumentar el trabajo de los motores de búsqueda. Eso puede afectar la velocidad y la frecuencia con la que éstos rastrean nuestras páginas nuevas y actualizadas.
Eso es malo porque puede provocar demoras en la indexación de páginas nuevas y la reindexación de páginas actualizadas.
Nota: Debido a que el límite de velocidad de rastreo de Google es más alto para los sitios web más receptivos, esto es más un problema para los sitios web lentos con menores márgenes de ancho de banda. Sus sistemas también rastrearán las URL duplicadas con menos frecuencia.
Contenido Scraped o sindicado que nos supera
Ocasionalmente, podemos permitir que otro sitio web vuelva a publicar nuestro contenido. Eso se conoce como sindicación. Otras veces, los sitios pueden raspar (Scraped) nuestro contenido y volver a publicarlo sin permiso.
Ambos escenarios conducen a contenidos duplicados en múltiples dominios. Sin embargo, por lo general no causan problemas. Solo cuando el contenido raspado o vuelto a publicar comienza a superar al original en nuestro sitio es cuando surgen los problemas.
La buena noticia es que esto es raro, pero puede suceder.
¿Google penaliza el contenido duplicado?
Google ha declarado en múltiples ocasiones que no penalizan el contenido duplicado.
“No tenemos una penalización por contenido duplicado. No es que degrademos un sitio por tener mucho contenido duplicado”. John Mueller, analista de tendencias para webmasters de Google.
“Aclaremos esto de una vez por todas, amigos: no existe una penalización por contenido duplicado”. Susan Moskwa, exanalista de tendencias de webmasters de Google.
“DYK Google no tiene una penalización por contenido duplicado”. Gary Illyes, analista de tendencias para webmasters de Google.
Sin embargo, esto no es del todo cierto. Si nuestro contenido duplicado es accidental y no es el resultado de una manipulación intencional de los resultados de búsqueda o prácticas de spam, entonces no será penalizado.
No obstante, Google confirma aquí:
“En los raros casos en los que Google percibe que se puede mostrar contenido duplicado con la intención de manipular nuestras clasificaciones y engañar a nuestros usuarios, también haremos los ajustes apropiados en la indexación y clasificación de los sitios involucrados. Como resultado, la clasificación del sitio puede verse afectada, o el sitio podría eliminarse por completo del índice de Google, en cuyo caso ya no aparecerá en los resultados de búsqueda”.
La pregunta es, ¿qué cuenta como intención de manipular nuestras clasificaciones y engañar a nuestros usuarios?
Google tiene mucha información sobre eso aquí. Pero básicamente, son cosas como:
- Crear intencionalmente múltiples páginas, subdominios o dominios con mucho contenido duplicado.
- Publicar mucho contenido raspado o Scraped.
- Publicar contenido afiliado extraído de Amazon u otros sitios (y sin agregar valor adicional).
Sin embargo, como se discutió anteriormente, el contenido duplicado puede dañar el SEO, incluso sin penalización.
Causas comunes de contenido duplicado
No hay una sola causa de contenido duplicado. Existen muchas.
La navegación por facetas ocurre cuando los usuarios pueden filtrar y ordenar elementos en la página. Los sitios web de comercio electrónico lo usan mucho.
Este tipo de navegación agrega parámetros al final de las URLs.
![]()
Debido a que generalmente hay muchas combinaciones de estos filtros, la navegación facetada a menudo resulta en mucho contenido duplicado o casi duplicado.
Echemos un vistazo a estas dos páginas, por ejemplo:
bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked bbclothing.co.uk/en-gb/clothing/shirts.html?Size=S&new_style=Checked
Las URLs son únicas, pero el contenido es casi idéntico.
Además, el orden de los parámetros a menudo no importa. Por ejemplo, se puede acceder a la misma página en ambas URL:
bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked & Size=XL bbclothing.co.uk/en-gb/clothing/shirts.html?Size=XL&new_style=Checked
¿Cómo resolver este problema?
La navegación por facetas es compleja. Si sospechamos que esta es la causa de nuestros problemas de contenido duplicado, recomendamos leer esta publicación.
Parámetros de seguimiento
Las URL parametrizadas también se utilizan con fines de hacer seguimiento a determinado parámetro. Por ejemplo, podemos usar los parámetros UTM para rastrear las visitas de una campaña de boletines en Google Analytics: Por ejemplo:
ejemplo.com/page?utm_source=newsletter
¿Cómo resolver este problema?
Canonizar nuestras URLs parametrizadas a versiones compatibles con SEO sin parámetros de seguimiento.
ID de sesión
Las ID de sesión almacenan información sobre nuestros visitantes. Por lo general, agregan una cadena larga a las URLs de la siguiente manera. Por ejemplo:
ejemplo.com?sessionId=jow8082345hnfn9234
¿Cómo resolver este problema?
Canonizar las URL a versiones compatibles con SEO.
HTTPS vs HTTP, y sin www vs www
La mayoría de los sitios web son accesibles en una de estas cuatro variaciones:
- https://www.ejemplo.com ( HTTPS, www)
- https://ejemplo.com ( HTTPS, sin www)
- http://www.ejemplo.com ( HTTP, www)
- http://ejemplo.com ( HTTP, sin www)
Si estamos utilizando HTTPS, será uno de los dos primeros. Si es la versión www o sin www quedará a nuestra elección.
Sin embargo, si no configuramos correctamente nuestro servidor, el sitio será accesible en dos o más de estas variaciones. Eso no es bueno y puede conducir a problemas de contenido duplicado.
¿Cómo resolver este problema?
Podemos usar redireccionamientos para asegurarnos de que nuestro sitio web solo sea accesible en una ubicación.
URLs sensibles a mayúsculas y minúsculas
Google ve las URLs como mayúsculas y minúsculas.
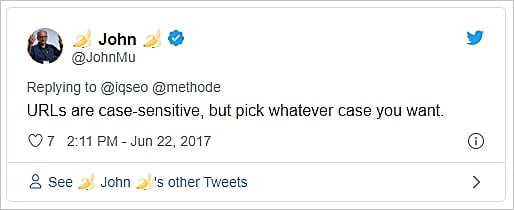
Nota: Este no parece ser el caso de Bing, que trata todas las URL como minúsculas.
Eso significa que estas tres URLs son todas diferentes:
- ejemplo.com/pagina
- ejemplo.com/PAGINA
- ejemplo.com/pAgInA
¿Cómo resolver este problema?
Debemos ser coherentes con los enlaces internos. Es decir, no enlacemos internamente a múltiples versiones de las URLs. Si eso no resuelve el problema, siempre podemos canonizar las URLs o redirigirlas.
Barras al final vs sin barras al final
Google trata las URLs con y sin barras inclinadas como únicas. Eso significa que estas dos URLs son únicas a los ojos de Google:
- ejemplo.com/pagina/
- ejemplo.com/pagina
Si se puede acceder a nuestro contenido en ambas URLs, eso puede generar problemas de contenido duplicado.
Para verificar si esto es un problema, intentemos cargar una página con y sin la barra diagonal final. Idealmente, solo se cargará una versión. La otra se redirigirá.
Por ejemplo, si intentamos cargar esta publicación sin la barra diagonal final, se redirigirá a la URL con la barra diagonal final.
Google afirma que este comportamiento es ideal.
Si solo se puede devolver una versión (es decir, la otra redirige a esta), esto resulta genial. Este comportamiento es beneficioso porque reduce el contenido duplicado.
¿Cómo resolver este problema?
Redirigir la versión no deseada. Por ejemplo, sin barra inclinada al final a la versión deseada con la barra inclinada al final. También debemos asegurarnos de mantenernos consistentes con los enlaces internos. No debemos vincularnos a versiones con barras diagonales a veces y otras veces no. Debemos elegir una opción y quedarnos con ella.
URLs fáciles de imprimir
Las versiones para imprimir tienen el mismo contenido que el original. Es solo la URL la que difiere.
- ejemplo.com/pagina
- ejemplo.com/print/pagina
¿Cómo resolver este problema?
Canonizar la versión para imprimir a la original.
URLs compatibles con dispositivos móviles
Las URLs para dispositivos móviles, como las URL para imprimir, se duplican.
- ejemplo.com/pagina
- m.ejemplo.com/pagina
¿Cómo resolver este problema?
Canonizar la versión optimizada para dispositivos móviles a la original. Usemos rel=»alternate» para indicarle a Google que la URL optimizada para dispositivos móviles es una versión alternativa del contenido de escritorio.
Lectura recomendada: anotaciones para URL de escritorio y móviles
URL de AMP
Las páginas móviles aceleradas (AMP) pueden aparecer duplicadas.
- ejemplo.com/pagina
- ejemplo.com/amp/pagina
¿Cómo resolver este problema?
Canonizar la versión AMP a la versión no AMP. Usemos rel=»amphtml» para indicarle a Google que la URL de AMP es una versión alternativa del contenido que no es AMP.
Si solo tenemos contenido AMP, usemos una etiqueta canónica autorreferenciada.
Lectura recomendada: Make your pages discoverable – Haga que sus páginas sean reconocibles – amp.dev
Páginas de etiquetas y categorías
La mayoría de los CMS crean páginas de etiquetas dedicadas cuando las usamos.
Por ejemplo, si tenemos un artículo sobre la proteína de suero orgánico y utilizamos tanto protein-powder como whey como etiquetas, terminaremos con dos páginas de etiquetas como estas:
https://www.caltonnutrition.com/tag/whey/ https://www.caltonnutrition.com/tag/protein-powder/
Eso no siempre causa contenido duplicado en sí mismo, pero puede ocurrir.
En este caso porque solo hay una página en el sitio con esas dos etiquetas, hace que cada página de etiquetas sea idéntica.
¿Cómo resolver este problema?
Existen dos opciones:
- No usar etiquetas. La mayoría de las veces, tienen poco o ningún valor de todos modos.
- No indexar nuestras páginas de etiquetas. Esto no resuelve el problema del retraso del rastreo, ya que Google aún perderá tiempo rastreando estas páginas.
Debemos tener en cuenta que las páginas de categorías pueden causar problemas similares a las páginas de etiquetas. Veamos el siguiente caso:
https://www.xs-stock.co.uk/adidas/ https://www.xs-stock.co.uk/brands/Chelsea-FC.html
Ambas páginas son casi idénticas porque no hay productos listados en ninguna de las categorías. Entonces, todo lo que nos queda es la copia de la plantilla repetitiva.
Podemos resolver esto utilizando un número razonable de categorías en nuestro sitio, o incluso sin indexar nuestras páginas de categorías.
URLs de imagen adjunta
Muchos CMS crean páginas dedicadas para adjuntar imágenes. Estas páginas generalmente no muestran más que la imagen y alguna copia repetitiva.
Debido a que esta copia es la misma en todas las páginas generadas automáticamente, esto conduce a contenido duplicado.
¿Cómo resolver este problema?
Podemos deshabilitar páginas dedicadas para imágenes en nuestro CMS. En WordPress, podemos hacer esto usando un plugin como Yoast.
Comentarios paginados
WordPress y otros CMS permiten comentarios paginados. Esto provoca contenido duplicado, ya que crea efectivamente múltiples versiones de las mismas URLs.
- ejemplo.com/post/
- ejemplo.com/post/comment-page‑2
- ejemplo.com/post/comment-page‑3
¿Cómo resolver este problema?
Desactivando la paginación de comentarios o no indexemos nuestras páginas paginadas utilizando un plugin como Yoast.
Localización
Si estamos sirviendo contenido similar a personas en diferentes lugares que hablan el mismo idioma, eso puede causar contenido duplicado.
Por ejemplo, podemos tener diferentes versiones de nuestro sitio para personas en los Estados Unidos, el Reino Unido y Australia. Debido a que es probable que solo existan pequeñas diferencias entre el contenido servido a cada localidad (por ejemplo, precios en dólares versus libras esterlinas), las versiones estarán casi duplicadas.
Nota: Según John Mueller de Google Suiza, el contenido traducido no es contenido duplicado.
¿Cómo resolver este problema?
Usando el atributo hreflang para informar a los motores de búsqueda sobre la relación entre las variaciones. Para caracterizar a una página web en inglés, podemos implementar el atributo hreflang acompañado del código de país «en». Por ejemplo:
<link rel="alternate" hreflang="en" href="URL de la web"/>
Páginas de resultados de búsqueda
Muchos sitios web tienen cuadros de búsqueda. El uso de estos, generalmente nos lleva a una URL de búsqueda parametrizada. Por ejemplo:
ejemplo.com?q=search-term
El ex jefe de spam web de Google, Matt Cutts, declaró lo siguiente:
“Por lo general, los resultados de búsqueda web no agregan valor a los usuarios, y dado que nuestro objetivo principal es proporcionar los mejores resultados de búsqueda posibles, generalmente excluimos los resultados de búsqueda de nuestro índice de búsqueda web. Por supuesto, no todas las URL que contienen elementos como /resultados o /búsqueda son resultados de búsqueda”. Matt Cutts, ex jefe de Webspam Google.
¿Cómo resolver este problema?
Usando una metaetiqueta de robots para eliminar páginas de búsqueda del índice de Google o bloquear el acceso a las páginas de resultados de búsqueda en robots.txt. Debemos abstenernos de vincular internamente a las páginas de resultados de búsqueda.
Entorno provisional
Un entorno provisional es una versión duplicada o casi duplicada de nuestro sitio que se utiliza con fines de prueba.
Por ejemplo, imaginemos que deseamos instalar un nuevo plugin o cambiar algún código en nuestro sitio web. Es posible que no deseemos llevar eso directamente a un sitio en vivo con cientos de miles de visitantes diarios. El riesgo de catástrofe es demasiado alto. La solución es probar primero los cambios en un entorno de ensayo o provisional.
Los entornos de ensayo se convierten en un problema de SEO cuando Google los indexa porque generan contenido duplicado.
¿Cómo resolver este problema?
Proteger nuestro entorno de ensayo mediante autenticación HTTP, lista blanca de IP o acceso VPN. Si ya está indexado, podemos usar una directiva noindex de robots para eliminarlo.
¿Cómo verificar si hay contenido duplicado en nuestro sitio?
Para saber si existe contenido duplicado en nuestro sitio web, nos vamos a Auditoría del sitio de Ahrefs y comenzamos a hacerle un rastreo a nuestro sitio web.
Una vez hecho esto, revisamos el Informe de calidad del contenido proporcionado por Ahrefs.
Buscamos los grupos de contenidos duplicados y casi duplicados sin un canónico. Estos aparecerán resaltados en color naranja.
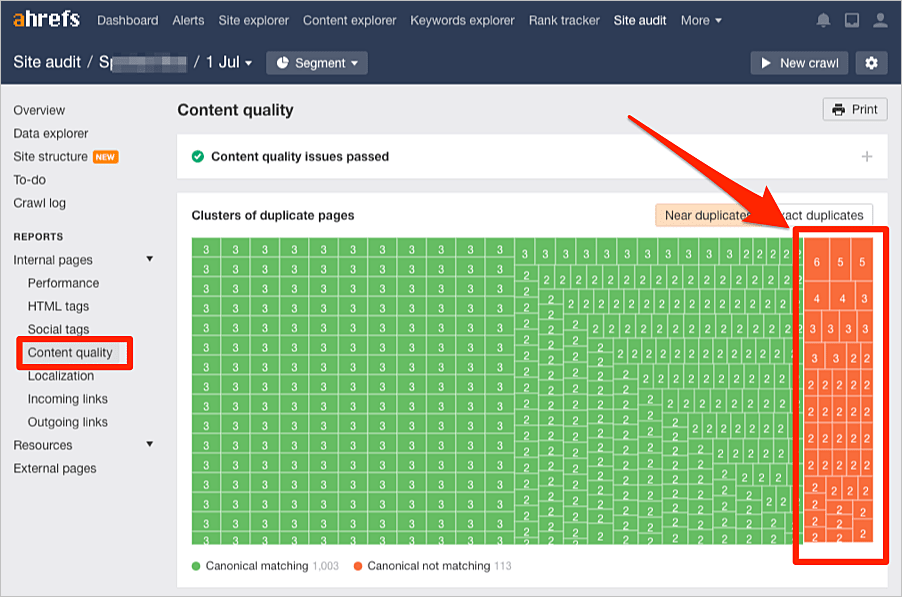
A continuación, hacemos clic en cualquiera de estos grupos para ver las páginas afectadas.
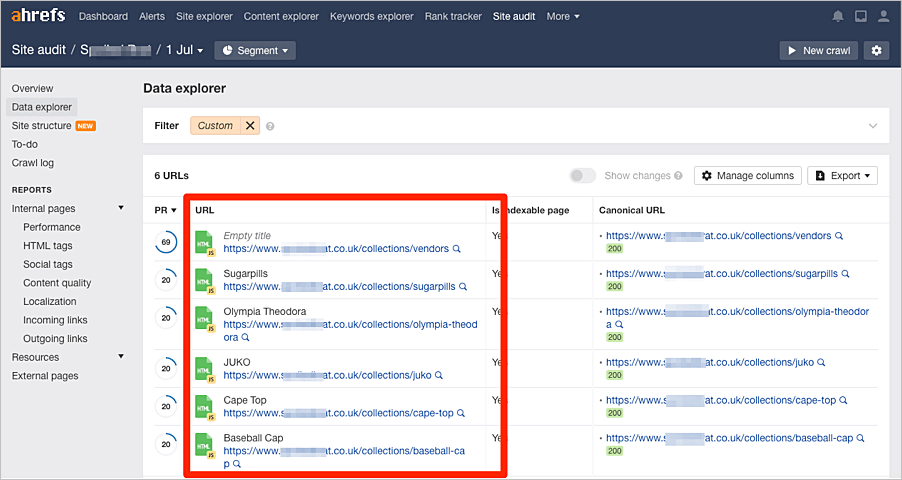
Investigamos la razón del contenido duplicado y posteriormente, tomamos las medidas apropiadas.
Debemos tener en cuenta que estos contenidos duplicados no siempre ocasionarán problemas que deben resolverse, especialmente en el caso de los casi duplicados.
En el caso de no tener una cuenta en Ahrefs, buscamos estas advertencias relacionadas con el contenido duplicado en Google Search Console:
- Duplicar sin canónico seleccionado por el usuario.
- Duplicado, Google eligió diferentes canónicos que los del usuario.
- Duplicado, URL enviada no seleccionada como canónica.
Podemos obtener más información sobre cómo manejar estas advertencias aquí.
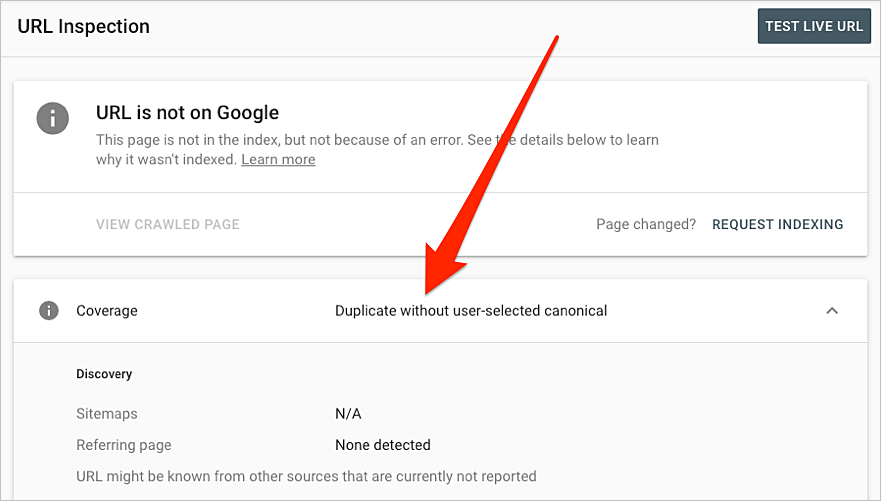
Herramienta de inspección de Google
Para ver cómo trata Google una URL específica, podemos usar la herramienta de inspección de URL de Google.
También podemos verificar si existen etiquetas de título duplicadas, metadescripciones y H1 en el informe de etiquetas HTML.
Los duplicados incorrectos son los que estamos buscando. Estas son páginas con metaetiquetas duplicadas pero con diferentes canónicos.
Podemos seleccionarlos haciendo clic en el botón Duplicados incorrectos en Etiquetas y contenido HTML.
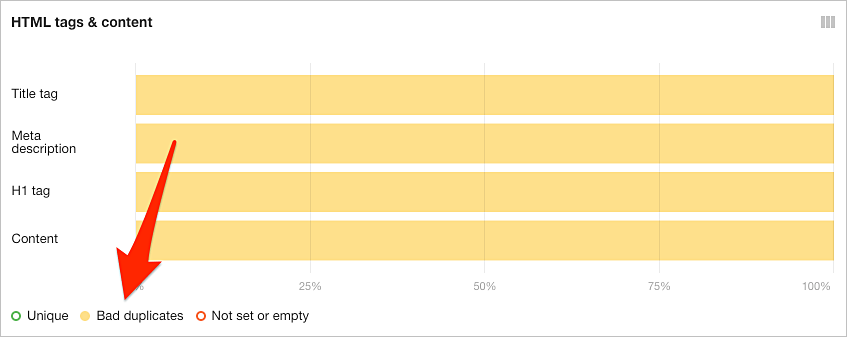
A continuación, hacemos clic en cualquiera de las barras amarillas para ver las páginas afectadas.
Las páginas con títulos duplicados, meta descripciones o H1 son a menudo muy similares.
Por ejemplo, estos dos tienen la misma etiqueta de título y el contenido es casi idéntico porque el producto es el mismo. La única diferencia es que una de las páginas es para un paquete de 3 de unidades de fuego de iluminación instantánea, mientras que la otra es solo para una unidad del producto.
https://www.xs-stock.co.uk/big-k-instant-light-the-wrapper-firelog-3-pack-camp-fire-fuel/ https://www.xs-stock.co.uk/big-k-instant-light-the-wrapper-firelog-camp-fire-chiminea/
Google afirma que debemos minimizar el contenido similar como este. Si tenemos muchas páginas que son similares, debemos considerar expandir cada página o consolidar las páginas en una sola. Sin embargo, es poco probable que un pequeño número de páginas similares sea un gran problema.
¿Cómo verificar si hay problemas de contenido duplicado en la web?
El raspado o Scraped y la sindicación de contenido también pueden generar problemas de contenido duplicado. Pero generalmente, solo es un problema si vemos versiones raspadas de nuestro contenido que nos superan.
¿Eso pasa? Sí, pero a menudo es más un problema para sitios web nuevos o débiles. Y esto es porque los sitios que raspan nuestro contenido a menudo son autoritarios. Eso a veces engaña a Google para que piense que el nuestro es el original.
Si tenemos un sitio web pequeño, a menudo podemos encontrar contenido raspado buscando en Google utilizando un fragmento de texto de nuestra página y colocándolo entre comillas.
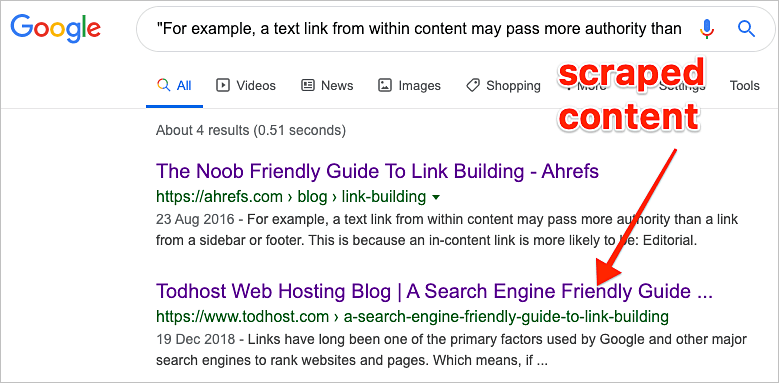
Para sitios más grandes, necesitaremos usar una herramienta automatizada como Copyscape. Este servicio web busca en toda la red otras similitudes con el contenido de nuestra(s) página(s).
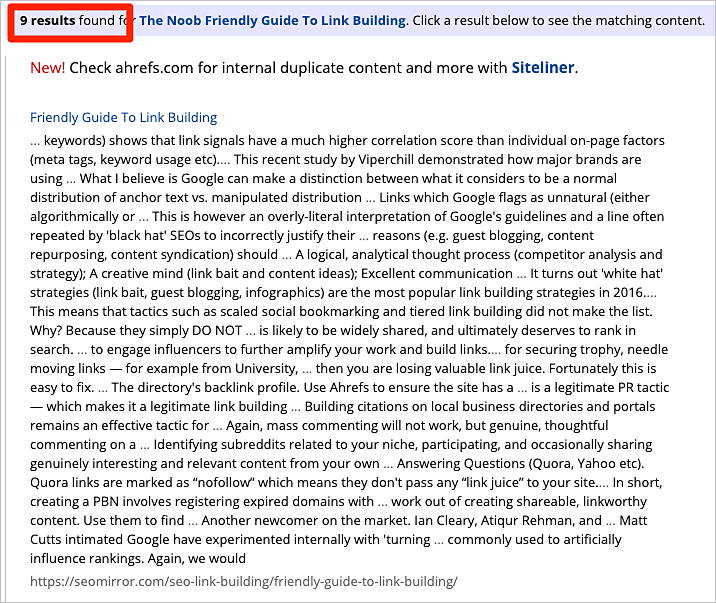
Cualquiera que sea el método que utilicemos, la mayoría de los resultados serán de spam y sitios de baja calidad.
En términos generales, no hay de qué preocuparse. Sin embargo, si vemos que un sitio web legítimo raspa nuestro contenido y nos preocupa que pueda estar robando nuestro tráfico, podemos colocar la URL en el Explorador de sitios de Ahrefs para ver una estimación del tráfico orgánico.
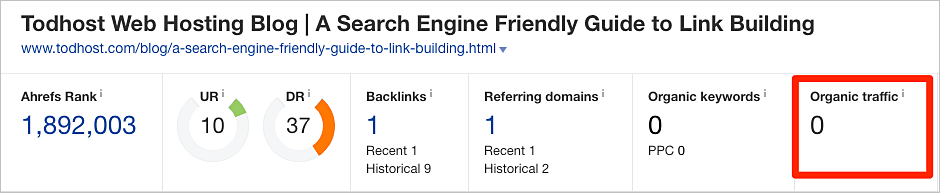
Si el sitio en cuestión obtiene más tráfico que nuestra página, puede haber un problema.
En este caso, tenemos tres opciones:
- Comunicarnos con ellos y solicitar que eliminen el contenido.
- Comunicarnos y solicitar que agreguen un enlace canónico al original en nuestro sitio.
- Enviar una solicitud de eliminación de DMCA a través de Google.
Si intencionalmente distribuimos contenido a otros sitios web, entonces vale la pena pedirles que agreguen un enlace canónico al original. Eso eliminará el riesgo de problemas de contenido duplicado.
Republicar contenido en nuestro propio sitio web
Si estamos republicando contenido de otros en nuestro sitio, existen dos formas de evitar problemas de contenido duplicado:
- Canonizar de nuevo al original.
- No indexar la página.
Conclusiones
No debemos preocuparnos demasiado por el contenido duplicado. Por lo general, es un problema mucho menor de lo que se cree.
Si tenemos un puñado de páginas duplicadas o casi duplicadas, es poco probable que haya un gran problema. Lo mismo es cierto al citar contenido de otro sitio web u otras páginas en nuestro sitio.
Pequeñas cantidades de contenido duplicado o repetitivo deberían estar bien. Google tiene sistemas establecidos para hacer frente a tales cosas.
Sin embargo, debemos estar atentos a los percances técnicos de SEO que conducen a la generación de cientos o miles de páginas de contenido duplicado. Percances como la implementación incorrecta de la navegación por facetas en los sitios de comercio electrónico.
Estos pueden causar estragos en nuestra cuota de rastreo, entre otras cosas.
Esperamos que esta guía completa de contenido duplicado, les haya resultado útil. Más información sobre este y otros temas en Ayuda Hosting.

